cafe
Retrieval-Augmented Generation (RAG) 란?
"Retrieval-Augmented Generation"은 자연어 처리(NLP)에서 사용되는 기술로, 텍스트 생성 과정에 정보 검색 과정을 통합하여 결과의 정확성과 관련성을 향상시키는 방법입니다. RAG 모델은 기존의 텍스트 생성 모델과 정보 검색 시스템을 결합하여, 주어진 쿼리에 대한 응답을 생성하기 전에 관련 정보를 검색하고, 이를 바탕으로 보다 정보에 기반한, 정확한 답변을 생성할 수 있게 해줍니다.
작동 방식
검색 단계: 주어진 입력에 기반해 관련 정보를 포함하는 문서나 데이터를 검색하는 단계입니다. 이 과정에서는 일반적으로 대규모의 문서 데이터베이스에서 입력 쿼리와 관련된 문서를 찾아냅니다.
통합 및 생성 단계: 검색된 정보를 기반으로, 생성 모델이 최종 텍스트를 생성합니다. 이 단계에서는 검색된 문서의 내용을 통합하여 입력 쿼리에 대한 응답을 생성하며, 이때 생성된 응답은 검색된 정보의 맥락을 반영합니다.
장점
정확도 향상: 검색된 문서에서 가져온 정보를 기반으로 하기 때문에, 생성된 텍스트가 보다 정확하고 신뢰할 수 있는 정보를 포함할 가능성이 높아집니다.
유연성: 다양한 종류의 쿼리에 대응할 수 있으며, 특정 분야의 지식이나 최신 정보가 필요할 때 특히 유용합니다.
RAG는 특히 정보 검색과 텍스트 생성을 결합하여 보다 정확하고 정보에 기반한 답변을 제공할 필요가 있는 챗봇, 검색 엔진, 자동 기사 작성 등 다양한 응용 분야에서 사용될 수 있습니다.
https://www.youtube.com/watch?v=m7cNjCVpSrw
이 영상을 들으면 좀더 이해가 된다. 내가 가진 데이터와 질문을 벡터DB에 넣고 가까운 결과 N건을 가져온후 LLM으로 프롬프트 이용해서 결과를 구성하는 방식인 것 같다. 보통 특수한 목적의 챗봇을 만들때 내가 가진 데이터가 정답셋일경우 이렇게 접근하면 유용한 챗봇을 만들수 있을 것 같다.
https://www.youtube.com/watch?v=KDM6UM-msZk
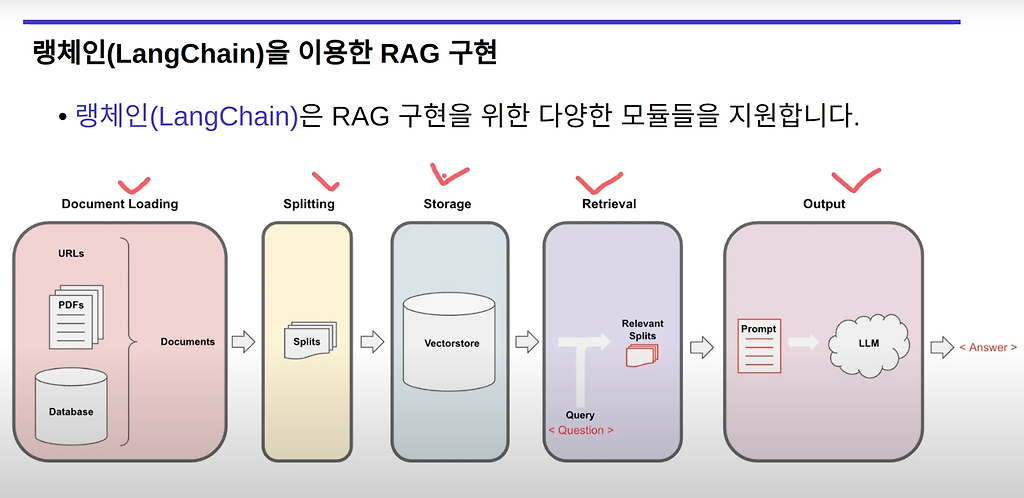
이 강의도 깔끔하다. 특히 아래 그림
댓글 쓰기